これは 東京大学 応用物理学系 Advent Calendar 2020 の21日目の記事です。前日20日の記事は、午前さんの「工学博覧会のキービジュアルを作った話(3DCGメイキング)」です。
TSG Advent Calendar 2020 の21日目の記事も同じ日に出ているので、そちらもよければ。ちなみになぜ同じ日なのかというと、サイコロが2連続で21を示したからです。
※ この記事は、私がSlackbotを作成している大まかな流れをそこはかとなく書き留めたものです。登場する各項目の詳しい解説は、ページ中の参考記事やドキュメント等を参照してください。
経緯
応用物理学系(※ 物理工学科と計数工学科をあわせた呼び名)アドカレではありますが、他の応物所属のプロたちと違って語れるほど学問の能はなく、さらに4コマ漫画の方たちみたいな創作力も持ち合わせていないので困りました。だとすれば、ぼくの唯一の応物との接点と言い張れる学科Slackbotを持ち出してくるしかないということで、今回も学科Slackbotです。この記事が出る頃に #2 が出ているかどうかわからないのですが[追記] #2は出てませんでした、とりあえず下書きにはあるので今回は #3 ということにしておきます。
やりたいこと
Advent Calendar(具体的にはAdventar)の登録したページを定期的に取得し、以下の情報の更新を検出したらSlackに投稿するbotを作ります。
- 空いている日が埋まった / 埋まっていた日が空いた
- 登録された記事が公開された / 取り下げられた
用語
Adventarの各アドカレのURLの末尾の数(例えば、https://adventar.org/calendars/4940 なら4940)を、pageIDと呼ぶことにします。
とにかく作る
スクレイピング
上記のデータを取得するために、とりあえず 東京大学 応用物理学系 Advent Calendar 2020 を開発者ツールで眺めてみると、以下のような構造になっていることがわかります。ちなみに、今後HTMLの各要素はtag.class、parent > childの形式で指定することにします。
- アドカレのタイトルは、
header.header中のh2.titleに記述されている - 埋まっている日の情報は
ul.EntryList > li.item中に、日ごとに登録されている- 日付と登録者は
div.headにある - 公開された記事のリンクは
div.article中のdiv.link > aのhref属性に記述されている
- 日付と登録者は
Node.jsでWebページのデータを取得する方法はいくつかあります。今回は欲しい情報の位置をclassで指定したい、すなわちgetElementsByClassNameメソッドを使いたいので、対象のページをDOMで扱えるjsdomパッケージを利用します。
これがなかなかえらくて、JSDOM.fromURL(url)の1行で、urlが示すWebページを取得して、そのデータからDOMのモデルの構築までできてしまいます。便利ですね。
それでは、pageIDを受け取ってそのアドカレのデータを取得して(Promiseを)返す関数fetchAdventarSnapshotを実装していきます。
まず、import { JSDOM } from 'jsdom';で、jsdomモジュールのJSDOMクラスをimportしておきます。次に、関数宣言の外で、アドカレのデータを保持するためのinterfaceを宣言しましょう。型を指定したいときに楽になるし(本当はもっといいことがあるのかもしれないけど何もわかっていない顔)。
interface AdventarArticle {
user: { uid: number; name: string; iconURI: string };
articleURI: string | null;
}
interface AdventarCalendarSnapshot {
title: string;
year: number;
pageID: number;
entryList: Array<AdventarArticle | null>;
}AdventarArticleは、各日付の記事の情報を保持するinterfaceです。記事がまだ公開されていない場合は、articleURIはnullになります。AdventarCalendarSnapshotは、(情報取得時点の)アドカレ全体の情報を保持するinterfaceです。yearは、何年のアドカレのデータか簡単にわかるように保持しておきます。entryListは配列であり、entryList[x]には12月x日に対応するAdventarArticleが入ります。
fetchAdventarSnapshot関数の返り値は、このAdventarCalendarSnapshotとします。
次にfetchAdventarSnapshot関数本体の実装をしていきます。受け取ったpageIDからAdventarのURLを生成し、先述したJSDOM.fromURLでページを取得します。
const url = `https://adventar.org/calendars/${pageID}`;
const document = (await JSDOM.fromURL(url)).window.document;このdocumentに対して、ブラウザでJavaScriptとを実行するのと同じようにgetElementsByClassNameメソッド等を用いることが出来ます。
const title = document.getElementsByClassName('title')[0].innerHTML;yearはtitleの末尾から取得することにします(Adventarでは、アドカレの名前の末尾に自動的に年が付加される)。
entryListもやっていきましょう。各記事の情報はul.EntryList内にありました。ul.EntryListには登録されていない日付の項目は存在しないので、mapだと登録されていない日付を扱いづらいです。なので、要素数26(日付と添字を一致させるため、0を捨てる)の配列を作り、forEachで対応する添字の場所に値をセットしていく形にします。
空の配列を作って…
const entryList = Array<AdventarArticle | null>(26).fill(null);forEachで処理していくぜ!
Array.from(
document.getElementsByClassName('EntryList')[0].childNodes
).forEach((entry) => {
const elemHead = entry.getElementsByClassName('head')[0];
const elemArticle = entry.getElementsByClassName('article')[0];
...(略)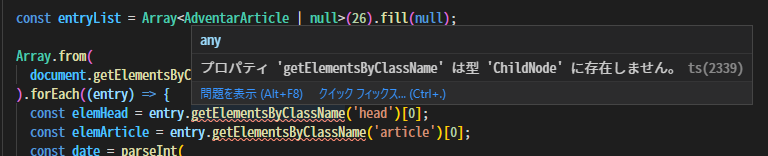
??????????????????
こういうときは、みんな大好きMDNを参照すると幸せになれることが知られています。というわけで
Node: childNodes プロパティ - Web API | MDN
childNodesにはテキストノードやコメントノードなどの非要素ノードを含むすべての子ノードが含まれます。要素のみのコレクションを取得するには、代わりにParentNode.childrenを使用してください。
なるほどですね。childNodesプロパティは、getElementsByClassNameメソッドを持つElementではなく、より上位のNodeというクラスの配列(のようなもの)を持っているために、Elementに特有なメソッドはエラーを吐かれるわけです。
丁寧に適切な方法まで示してくれていますね。ElementはParentNodeクラスも継承しているので、childrenプロパティを使うことにしましょう。
Array.from(
document.getElementsByClassName('EntryList')[0].children
).forEach((entry) => {
const elemHead = entry.getElementsByClassName('head')[0];
const elemArticle = entry.getElementsByClassName('article')[0];
...(略)完成したfetchAdventarSnapshot関数は以下のようになりました。404の場合などのエラーは上位でキャッチすることにします。
const fetchAdventarSnapshot = async (pageID: number) => {
const url = `https://adventar.org/calendars/${pageID}`;
const document = (await JSDOM.fromURL(url)).window.document;
const title = document.getElementsByClassName('title')[0].innerHTML;
const year = (() => {
const matchedYear = title.match(/(\d+)$/);
assert(matchedYear);
return parseInt(matchedYear[1]);
})();
const entryList = Array<AdventarArticle | null>(26).fill(null);
Array.from(document.getElementsByClassName('EntryList')[0].children).forEach(
(entry) => {
const elemHead = entry.getElementsByClassName('head')[0];
const elemArticle = entry.getElementsByClassName('article')[0];
const date = parseInt(
elemHead.getElementsByClassName('date')[0].innerHTML.substr(3),
10
);
const user = {
uid: parseInt(
(elemHead
.getElementsByTagName('a')[0]
.getAttribute('href') as string).substr(7)
),
name: elemHead.getElementsByTagName('a')[0].innerHTML,
iconURI: elemHead
.getElementsByTagName('img')[0]
.getAttribute('src') as string,
};
const articleURI = elemArticle
? elemArticle.getElementsByTagName('a')[0].getAttribute('href')
: null;
entryList[date] = { user, articleURI };
}
);
return {
title,
year,
pageID,
entryList,
} as AdventarCalendarSnapshot;
};実際に挙動を試してみましょう。関数定義の後に以下のように記述してts-nodeで実行してみます。fetchAdventarSnapshotはasync関数なので、Promise(一旦別の場所で処理させておき、結果が出たときに渡した関数を実行してもらう非同期処理を実現するオブジェクト)を返すので、thenメソッドで処理内容を出力してもらうようにセットします。
fetchAdventarSnapshot(4940).then((data: any) => console.log(data));出力例:
settyan117@dev:~/user/ap2021bot$ npx ts-node testFetch.ts
{
title: '物工/計数 Advent Calendar 2020',
year: 2020,
pageID: 4940,
entryList: [
null,
{
user: [Object],
articleURI: 'https://drive.google.com/file/d/1HBlqmXQuuu9OLZF-Ey_qh3R99NVEHNcm/view?usp=drivesdk'
},
{
user: [Object],
articleURI: 'https://mathlog.info/articles/1141'
},
...(略)なんかそれっぽいのが出てきてくれました。やったぜ。すでに記事が出始めてるあたりいつ書きはじめたかがバレる
データベースへの接続
現在、学科SlackbotはHerokuの無料分で運用しているんですが、Herokuでは永続的にファイルを保存することが出来ない(再起動されると消えてしまう)んですよね。今回のbotは過去に取得したアドカレのデータを今のデータと比較する仕様なので、前のデータを保存しておく場所をどこかに用意しなければなりません。といった趣旨の内容をサークルのSlackで嘆いていたら、「無料で使えるデータベースがある」みたいなことを教えてくれたので使うことにしました。
というわけで、「MongoDB Atlas」というクラウドのデータベースを使っていきます。月額課金制ですが、共有サーバーで512MBまでは無料で利用できるっぽい。
MongoDBはNoSQL(関係データベースではないデータベース)の一種で、JSONのような形式の「ドキュメント」を「コレクション」の中に入れておく構造になっています。RDB以外知らなかった(RDBをまともに触ったことがあるとは言っていない)のですが、JavaScriptのオブジェクトをほとんどそのまま扱えるので、今回みたいな単純なシステムに使う分にはよさそう。
Get started with MongoDB — MongoDB Documentation

とりあえず試してみた(MongoDBの接続URLがすでに.envファイルにセットしてあります)。
import mongodb from 'mongodb';
const MongoClient = mongodb.MongoClient;
const testMongo = async () => {
require('dotenv').config();
const client = await MongoClient.connect(process.env.MONGODB_URI as string, {
useUnifiedTopology: true,
});
const db = client.db('testdb');
console.log('db connected');
console.log(await db.collection('testcl').find({}).toArray());
await db.collection('testcl').insertOne({ hoge: 'fuga', piyo: 123 });
console.log('inserted');
console.log(db.collection('testcl').find({ hoge: 'fuga' }).toArray());
await db.collection('testcl').updateOne({ hoge: 'fuga' }, { $set: { piyo: 456 } });
console.log('updated');
console.log(db.collection('testcl').find({ hoge: 'fuga' }).toArray());
client.close();
};
testMongo();7-9行目でMongoDBのサーバーに接続しています。オプションで渡している{ useUnifiedTopology: true }が何を意味するのかはまだ完全理解できていない(は?)ので、理解できたら追記します。とりあえず、つけないと DeprecationWarning が出ます。将来的にデフォルト値がtrueになるっぽい。
12行目でtestdbデータベースのtestclコレクションに含まれるドキュメントを出力しています(正確には、findメソッドでカーソルが作られ、カーソルのtoArrayメソッドで実際にドキュメントfindメソッドの引数にはオブジェクト形式で検索条件を記述でき、12行目の{}だとすべてのドキュメントが、16行目の例ではhogeプロパティが'fuga'であるドキュメントが抽出されます。他にも「以上/以下」などより複雑な条件の記法もあるけど、割愛。
出力例:
settyan117@dev:~/user/ap2021bot$ npx ts-node testMongo.ts
db connected
[]
inserted
[ { _id: 5fdf3e2001d7536f1b95a36a, hoge: 'fuga', piyo: 123 } ]
updated
[ { _id: 5fdf3e2001d7536f1b95a36a, hoge: 'fuga', piyo: 456 } ]
今回の用途ではこれだけできれば十分ですね。ちなみに、_idというプロパティはドキュメントの挿入時に自動で設定されるもので、更新では変化しません。
できた
長いのでGitHubのリンクを貼ります。
ap2021bot/src/adventar/index.ts at main · ut-ap2021/ap2021bot · GitHub
地味に、今年以前のアドカレは登録できない機能をつけていたりします。完了したアドカレを削除する機能はつけていないんですが、まあそこは手動ということで(実装がめんどかった)。
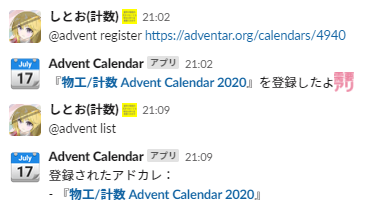
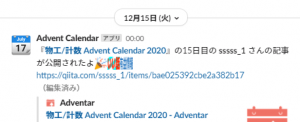
動作例
まとめ
- アドカレ(Adventar)の更新を通知するSlackbotを作った
以上です。明日22日の記事は、かいちょさんの「工学博覧会2020を振り返る」です。お楽しみに!